「HTML鳩丸倶楽部」の更新履歴、あるいは私のHTML研究日記、もしくは独り言です。
……しかし、じゃあ何が適切な例なんだと言われると分からないので、とりあえず削除しっぱなしになっています。情報、ご意見などお持ちの方がいらっしゃいましたら、メールでご連絡頂くか、新生鳩丸掲示板♯の記事1327からのスレッドに書き込んで頂けると助かります。
トップから鳩丸ぐろっさり (用語集)にリンクしてみたり。
リニューアル計画挫折中。完成後公開を目指すのはやめて、段階的に公開していこう……。
もはや HTML 関係の話題もえび日記の方に書いていたりするので、トップからリンクしてみたり。
本当は全面書き直しが必要ですが、それはまあリニューアルの時にと言うことで。
っていつリニューアルできるのだろう。まだ日記と掲示板しかできてない……。
コンテンツの更新はありません。なんかぜんぜん更新できていなくてごめんなさい。
年内にはなんとかリニューアル公開したいのですが……。
はっきり言って鳩丸はショボイです。たとえば:
さらに、全体的に内容が古いので、今の私の見解とは正反対のことを言っている部分もあります。たとえば table の summary についてとか。
そんなわけで、近々時間が出来たら構成を含めて内容を大幅に見直したいと考えている今日この頃であります。
Windows版IE5.5以降はCSSでwriting-mode:tb-rl;とやると縦書きにできる。IEの独自プロパティかと思ったらCSS3らしい。
せっかくなのでポインタを示しておくと、CSS3 module: text の 3.2. Setting the inline and block progressions: the 'writing-mode' and 'direction' properties にて提案されています。まだ WD ですが。
デザインをないがしろにしているくせに、他人のサイトのデザインにケチを付けるなんて、出過ぎたマネをしないで欲しい。
違う。他人のデザインにケチを付けているのでは無い。
デザインの実現方法にケチを付けているのだ。
「デザイン」という言葉の意味するところはかなり曖昧だと思います。特にそれが紙媒体における「デザイン」ではなく Webにおけるデザイン、いわゆる「Webデザイン」を指しているのであれば、なおさらです。
実は私も少し前までは「Webデザイン」という概念を紙媒体上でのデザインと同じようなものとしてとらえていました。だから、「デザイナーはアクセシビリティというものが分かっていない」とか「デザインとアクセシビリティとは水と油だ」などということを平気で思っていて、大昔の FMHPG ではそう言ったりもしていたのです。
しかし、本当に Web デザイン生業としているプロのデザイナーに出会って、その人の話を聞いた瞬間、そんな考えは一瞬にして消え去りました。
何のことはない、プロのデザイナーは「アクセシビリティ」だとか「ユーザビリティ」だとか言う概念をちゃんと知っていて、そういった要素も含めてデザインをしているのです。そこでは「Web デザイン」は、「アクセシビリティ」や「ユーザビリティ」と相容れない概念でも、全く別の概念でもなく、むしろそれらを含む概念として捉えられていると感じました。
かつての私は、多重の table でレイアウトされ文字サイズが固定された「特定環境で見ると美しい」ようなサイトについて、「デザインは良いがアクセス性に欠ける」と評価していました。しかし、今の私は同じ物を「ビジュアルは良いがアクセス性に欠けるデザイン」と評価します。「アクセス性を高く」設計することもまたデザインなのです。「CSS を使うことによってアクセス性を向上させる」という選択も、「table でレイアウトすることによって Netscape4 などでも擬似的にレイアウトを再現する」という選択も、それ自体が既に Web デザインの一環なのです。
鳩丸では後者のデザインは絶対にダメだとまでは言っていませんが、ダサイ、ショボイ、カッコ悪いデザインだと評価をしていることは間違いありません。そう考えると、私はまさに他人のデザインそのものにケチをつけているのであって、それをデザインをないがしろにしているくせに、他人のサイトのデザインにケチを付けるなんて、出過ぎたマネ
と言われても、それはそれでそんなに間違っていないと思うのです。
大昔に「Webアーティスト」云々という話がありましたが、そこで私が言いたかったのは、要するにこういうことなのです。外面に現れない属性であるとかソースであるとか、そう言った部分まで全て含めた意味での「デザイン」、これを極めてこその「アート」なのではないかと。当時はデザイナーという職種の人と触れあう機会もあまり無く、そのため「デザイナーという職種の人はみんな外見的な見栄えだけを重視している」などという妙な偏見がありました。今同じ趣旨のものを書けば、もっと良いものを書けるような気がします。
でも暇がない……。
IE6 において、「インターネットオプション」の「セキュリティ」タブでもって制限付きサイトゾーンのセキュリティレベルをカスタマイズして、「IFRAME のプログラムとファイルの起動」を「無効」にすると、何故か iframe のみならず frame まで無効になり、しかも noframes の内容も表示されないという状態になります。八方ふさがり。
ここで言う「IFRAME」には frame も含まれているのかと思いきや、同じ項目を「無効」ではなく「ダイアログを表示」にすると、今度は frame に出会ってもダイアログも何も出ずに有効になるのですから訳が分かりません。IE6 のバグと思われます。
IIS でコンテント・ネゴシエーションを実現する方法を調べようと思い、google で「IIS コンテント・ネゴシエーション」あたりを検索したのですが、なんか見たことのあるサイトばかり数件ヒットしただけで、収穫なし。IIS ってコンテント・ネゴシエーションに対応していないのでしょうか?
LWPでもって
use LWP::UserAgent; my $uri = 'http://member.nifty.ne.jp/bakera/html/hatomaru.html'; my $ua = new LWP::UserAgent; my $request = new HTTP::Request GET => $uri; my $responce = $ua->request($request); print $responce->headers_as_string();
などとやるとヘッダが取れますが、なんと HTTP 応答ヘッダだけでなく、HTML の中の META http-equiv の内容まで反映されています! 小さな親切大きなお世話……。Another HTML-lint Gateway で HTTP 応答ヘッダを表示させると Content-Type がダブったりすることがありますが、どうも LWP が原因のようです。
しかも 302 なんかが返ってくると LWP 自身がリダイレクトを処理して勝手にリダイレクト先のリソースにアクセスする! うーむ……。
配列へのリファレンスをハッシュに格納し、それをデリファレンスしようとしたらハマりました。
my @test = (1,2,3);
my %foo;
$foo{test} = \@test;
print @$foo{test};
これでは駄目。正解は
my @test = (1,2,3);
my %foo;
$foo{test} = \@test;
print @{$foo{test}};
と、{ } がもう一つ必要。
Netscape4 系でもって
var obj = new Date(); obj.setYear(obj.getYear);
などというスクリプトを実行すると、get したものをそのまま set しているだけにもかかわらず、西暦102年になったりして笑えました。
nifty:FHPBGN/MES/2/1604、Webページの横幅はどれくらいがいい? というありがちな、そして何度となく繰り返されてきた質問である。回答もありがちな、現在の機械の一般的と思われる画面の横幅はうんたらだからというものだ。何回やったら気が済むんですかね。せめて個人のサイトくらい、テーブルで横幅固定という悪しき伝統から脱して欲しいものだが。
個人のサイトだからいいや、という意見をつい最近どこかで見たような見ないような。
まあそれはともかく、横幅をピクセル単位などで指定していると、横にはみ出ることがあります。横スクロールバーが鬱陶しいと言われるのはありがちなシナリオですが、本当に困るのは印刷したときで、横が切れたらこれはもうどうしようもありません。
完全に CSS で制御しているなら CSS を差し替えるだけで何とかなりますが、横幅固定のサイトは多くの場合横幅を HTML 中に直接書いているので……。
印刷されることが予想できるようなリソースは、フレームにしたり横幅固定にしたりしないのが吉だと強く思う今日この頃なのでありました。
「URI の中に & を書くべからず」をちょこっと更新。
故あってハードディスクをフォーマットしたのでいろいろ再インストール。ActivePerl をインストール後、レジストリをいろいろいじって右クリックで perl -cw できるようにするのですが、面倒なのでレジストリファイルを作って読み込ませることにしました。ちなみに以下のような感じになりました。
Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\.cgi] @="Perl" [HKEY_CLASSES_ROOT\Perl] @="Perl File" "EditFlags"=dword:00000000 "BrowserFlags"=dword:00000008 [HKEY_CLASSES_ROOT\Perl\DefaultIcon] @="C:\\Perl\\bin\\Perl.exe,0" [HKEY_CLASSES_ROOT\Perl\Shell] @="edit" [HKEY_CLASSES_ROOT\Perl\Shell\bakera] @="文法チェック(&c)" [HKEY_CLASSES_ROOT\Perl\Shell\bakera\command] @="C:\\Windows\\system32\\cmd.exe /K C:\\Perl\\bin\\Perl.exe -cw \"%1\" %*" [HKEY_CLASSES_ROOT\Perl\Shell\edit] [HKEY_CLASSES_ROOT\Perl\Shell\edit\command] @="C:\\Windows\\notepad.exe \"%1\"" [HKEY_CLASSES_ROOT\Perl\Shell\Open] [HKEY_CLASSES_ROOT\Perl\Shell\Open\command] @="C:\\Windows\\system32\\cmd.exe /K C:\\Perl\\bin\\Perl.exe \"%1\" %*"
まあなんというか、参考にしたい方は参考にしてみてください。ちなみに、Windows 2000 や 2000 からアップデートした XP だと cmd.exe の場所が違ったりするので注意。非 NT 系だと cmd.exe の代わりに command.com で動きます。
「半角カナは機種依存文字か?」に UTF-7 の話をちょこっとだけ追加。
JavaScript でもって window.open するとき、たとえば
var newWin = window.open("about.html", 'test');
として開いたとします。このときウィンドウの名前は test になるわけですが、ウィンドウオブジェクトに対して操作するときにはオブジェクトに対して操作するわけですから、
newWin.focus();
となるのが正解で、test.focus(); としても動作しません。
P3Pが Recommendation になっておりますな。とりあえず鳩丸掲示板がコンパクトポリシーを吐くようにしてみようかしら……。
質問の場所が不適切な場合や、質問の方法が不適切な場合は、それを指摘すれば良いような気がします。ですが、その両方が不適切な場合は対処に困ります。しかも明らかに変な納得の仕方をしているという……。
ま、コメントする義務もないわけですし、とりあえず放置が一番なのかも。
先日の@niftyのトップが読めないって件、あれってimgとは関係ないようですね、スタイルシートに非対応だと全滅なのでは。最近は、スタイルシートやJavaScriptが使えないブラウザは切り捨てる方針になったか。
中途半端にスタイルシートを使って読めなくなった典型例ですな。特定部分の背景色だけが CSS で指定されているので、CSS が無効になると読めません。前景色も CSS で指定されていたならば微塵も問題ないわけで、「スタイルシートでしか表現できないものにだけスタイルシートを使う」という方法の問題点はそのあたりにあります。スタイルシートを使うなら全てをスタイルシートで指定するのが基本です。ってのはもう5年も前から言っているわけですが。
統合Windows認証はそもそも HTTP で認証を行うものではないので、Proxy が挟まっていたりするとアウトのようです。これは宿命であり、横取り丸が変だという事ではありません。
ちなみにサーバ側で認証方法を変更するには、管理ツールから IIS を開いて所定のディレクトリのプロパティを出し、「ディレクトリセキュリティ」タブの「匿名アクセスおよび認証コントロール」の所の「編集」ボタンを押してやれば設定項目があります。
どうも横取り丸を使っていると WebDAV の認証がうまくいかない模様。WebDAV クライアントは IE6、サーバは IIS5.1 なので「統合Windows認証」が使われていて、それがうまくいっていない可能性大。って、その認証がどういう仕組みなのか良く知らないのですが……調べねば。
それで WebDAV によるファイル共有が死んだのはまあ分かるのですが、意外なことに MSN Messanger も死にました。実は MSN Messanger も HTTP でデータをやりとりしていたのですなぁ。
あとアドレス補完機能は余計なお世話という気がする。http://example.com/ と http://example.com/index.html はそれぞれ別のリソースを示すURLだから、勝手に補完するのは良くない。同じものが返ってくるというのはたまたまそうなっているに過ぎない。動かない件も含めてメーろうかな。
良くない……というか、http://www.ne.jp/asahi/minazuki/bakera/html/hatomaru と入れたら http://www.ne.jp/asahi/minazuki/bakera/html/hatomaru/index.html を見に行くとなると、鳩丸本家のリソースは読めない(リンクを辿るたびに凄いことになる)と思われます。
新生鳩丸掲示板で satoshii さんにご指摘頂きましたが、そもそも
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML; CHARSET="SIFT_JIS">
って content属性の値は "TEXT/HTML; CHARSET=" で、タグの中に SIFT_JIS" という謎の文字列が出現している、というわけの分からない状況なのでした。こりゃ固まって当然ですわ。
「Japan.internet.com WebTutorial - トップ10サイトの比較検証 -- 3」ですが、JavaScript に関する論評に異議あり。
まず思ったのは、どうして「これらのサイトがスクリプトを利用している」ということから、「ユーザはスクリプトをオフにしていない」という結論が出るのかと言うことです。それらのサイトが、「スクリプト無効であれば全くアクセスできない」という悲惨な状況であるならまだ分かりますが、おそらくそんなことはないでしょう。ユーザはスクリプトを無効にして、そしらぬ顔で利用しているのかもしれません。
で、次に思ったのは、そもそもこの分析自体がたわけているということです。スクリプトに関しては「使用しているかしていないか」だけしか見ていませんが、一口にスクリプトを使用していると言っても、その使われ方は様々です。少し例を挙げてみると、
使われ方は全く違っています。これをひとまとめにして「スクリプトを使っている」として評価するのは乱暴です。ここでは「スクリプトが使われているか否か」よりも、「スクリプト無効でも問題なくアクセスできるか否か」という視点が重要ではないでしょうか。私の予想では、それらのサイトのほとんどは、スクリプトが無効であっても問題なくアクセスできるように設計されているはずです。
あと、ユーザがスクリプトを無効にする理由として「ポップアップウィンドウを表示させない」という理由が挙げられていますが、このへんもショボイと思いました。そういう理由でスクリプトを無効にしている人もおそらくいるでしょうが、私がスクリプトを無効にしている理由を問われたなら、まずはセキュリティ上の理由を掲げます。スクリプトが無効であれば、クロスサイトスクリプティング脆弱性が存在するサイトでも Cookie を盗まれる事はまずありませんし、その他の悪意あるスクリプトも実行されません。スクリプトを無効にしていれば防げるセキュリティホゥルは過去にいくつもありましたし、これからも出てくるでしょう。
セキュリティ上の問題が全くなければ、スクリプトは有効の方が良いに決まっています。なぜなら、大半のサイトではスクリプト有効の方が高いユーザビリティを得られるからです。スクリプトは使い方を誤ると、全くアクセスできないページを生んだりします。しかし、それは単に使い方が悪いのです。うまく利用すればユーザビリティやアクセシビリティを向上させることができます。たとえば tDiary の「謎JavaScript」などは良い例でしょう。
私自身、スクリプトをオフにしているユーザが多いとは思わないのですが、それにしてもこの分析は残念だと思います。
びいさんの日記に http://www.accsjp.or.jp/ のレスポンスが変だという話が出ていたので、取得してみました。私が取得したらこんな感じでした。
HTTP/1.1 200 OK Date: Fri, 05 Apr 2002 03:45:29 GMT Server: Apache/1.2.6 Last-Modified: Mon, 03 Apr 2000 09:15:31 GMT ETag: "5186c-235-38e86133" Content-Length: 565 Accept-Ranges: bytes Content-Type: text/html <HTML> <HEAD> <META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML; CHARSET="SIFT_JIS"> <META NAME="AUTHOR" CONTENT="TCS"> <META NAME="KEYWAORD" CONTENT="ソフトウェア,管理,調査,報告, コンピュータ,著作権,著作権協会,ACCS,ACCS"> <TITLE>(社)コンピュータソフトウェア著作権協会</TITLE> </HEAD> <FRAMESET COLS="160,*" BORDER=0 FRAMEBORDER=0 FRAMESPACING=0> <FRAME SRC="menu.html" NAME="left"> <FRAMESET ROWS="74,*" BORDER=0 FRAMEBORDER=0 FRAMESPACING=0> <FRAME SRC="title.html" NAME="over"> <FRAME SRC="top.html" NAME="main"> </FRAMESET> </FRAMESET>
ちゃんとヘッダ後の CR+LF は出力されていますし、body 中にもたくさん改行があるので、びいさんの取得経路のどこかで CR+LF がタブか何かに化けているのではないかと。で、固まったのはむしろ CHARSET=SIFT_JIS というのが原因なのではないかという気がします。シフトジスではなくスィフトジスになっているというのもありますが、その前に CR+LF が入っているのが破壊的な気がします。
"KEYWAORD" というのもありますが、こちらは害はなさそうです。意味は分かりませんが。
って、Apache 1.2.6 ですか? DoS なんかかけなくても、もっと有効な別の攻略法がありそうな気が……。
DSN を装ったウィルスメーをゲット。postmaster@star.email.ne.jp からのメーが cnpack.org[202.214.129.125] から送られてくるわけがありません。それ以前に、そもそも DSN の From: は postmaster ではなく MAILER-DAEMON になっているのが普通では? 間抜けというか何というか……。
ウィルス本体と思われるファイルは rel.pif という名前で、Content-Tramsfer-Encoding が Base64 なのに中身は生の 8-bit になっていました。Badtrans っぽいですが、Badtrans は DSN を装ったりはしなかったと思うので、Badtrans の亜種といったところでしょうか。
「SGMLの短縮タグ機構」と「CSSリファレンス - 書字方向」の typo を修正。
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Internet Settings\User Agent\Pre Platform] に、「"」やら「<」やらを含むいろいろな名前の文字列を作ってみたり。ちなみに値ではなく名前が使われるので注意。
P3Pはまだ PR なのですが、IE6 が実装したおかげで妙に普及している模様。このページの上についている(かもしれない) Value Click のバナーも、
HTTP/1.0 302 Found Date: Tue, 02 Apr 2002 11:26:49 GMT Server: Apache/1.3.17 (Unix) mod_perl/1.25 Set-Cookie: ksa=0PKmVeT15-WUAAK4C2mw1ae166ac; domain=.valueclick.ne.jp; path=/; expires=Sat, 27-Mar-2027 11:26:49 GMT Set-Cookie: r622EDA8A=BD9aJSE+S+WS0frwlBk++:; domain=.valueclick.ne.jp; path=/ Ad-Reach: valueclick.ne.jp Pragma: no-cache Cache-Control: private, max-age=0, no-cache P3P: CP='NOI DEVo TAIo PSAo PSDo OUR IND UNI NAV' policyref="/w3c/p3p.xml" Ad-Reach: valueclick.ne.jp Location: http://st.valueclick.ne.jp/ad.s/a0022527.gif Content-Length: 0
と言う感じでコンパクトポリシーを返しています(P3P: というフィールド)。
墓場で語られたところによると、高校の「情報」の教科書が凄いらしく、かなり「のけぞる本」であるらしいのです。検定はどうなってるのか、などとイロイロ盛り上がる要素があるわけで、検索してみたのですが。
なんかイマイチ。歴史教科書については中学校歴史教科書に関する検定結果というのがあったりするのですが。
家永教科書検定訴訟第3次訴訟・上告審判決(大野判決)なんてのも出てきましたが、これは役に立つのでメモしておきます。私が勉強していた当時はまだ第三次訴訟が係争中で、結果が出ていなかったので(とか言いつつ、当時勉強したことも忘れていますが……。結局、「731部隊の存在は当時から既に定説であった」と認定して、731部隊に関する記述を削除するよう求めた検定意見も違法とされ、違法と確定した検定箇所は合計4箇所となりました)。
某方面とは別個のクロスサイトスクリプティング脆弱性を発見。こっちは EC サイトなのでヤバさ100倍です。
某方面のクロスサイトスクリプティング脆弱性の話ですが、その後の調査でさらに強烈なホゥルを発見しました。特定の URL にアクセスすることで任意のホストの任意のポートにアクセス要求を出すことが可能です。実際には、そういった外へのリクエストはファイアーウォールに阻まれて外には出ない……と思いきや、試してみるとしっかり外部のホストにログが残る始末。コレを悪用すれば、任意のホストに対して簡単に DoS 攻撃が行えます。クロスサイトスクリプティング脆弱性どころの騒ぎではありません。
しかもこのシステム、単独で開発されたものではなく、某方面の関連会社が作った製品らしい事が判明しました。某方面総合トップのみならず、その方面全体で広く使われているほか、某地方公共団体のサイトにも使われています。もちろん、それらすべてにホゥルが存在しています。
いやーすばらしい。
とりあえずセキュリティホール memo 方面に流す……のもある意味危険なので、小島さんに直メーで告げ口したりするのが良かったりするのでしょうか。
とりあえず秀丸ユーザになったのでメモしておきます。
某方面のクロスサイトスクリプティング脆弱性は解消した模様。
果敢にも報告してくれた一都民に感謝いたします。
前言撤回。検索キーワードだけしか対処されていない模様。……何も考えてないですな。
しばらく見ないうちに、IANA の media-types がパワーアップしておりました。昔はテキストファイル一つだったというのに……。
HTTP/1.1 400 Bad Request Server: Netscape-Enterprise/3.6 SP3 あなたのブラウザがサーバに送ったリクエストはサーバが理解できないリクエストです。
Content-Type も何も無しというのは 400 応答としては問題ないのかもしれませんが、日本語のテキストを送ってくるあたりが素晴らしいです。ちなみに EUC-JP でした。
備考 数又は数字句は,数値ではなく,名前又は名前字句と同じく文字列に過ぎ ない。したがって,例えば“01”と“1”とは同値でない。
某方面の総合トップページが更新されたという話を聞いて見に行ったとき、思いっきりクロスサイトスクリプティング脆弱性を発見してしまいました。連絡しようかと思ったのですが、連絡用のフォームには「電話番号が必須」などと書いてあったので連絡する気が萎えてしまい、放置。とは言えクロスサイトスクリプティング脆弱性は放置すると危険なので、とりあえずそのサイトを「制限付きサイトゾーン」に登録することで回避しました。
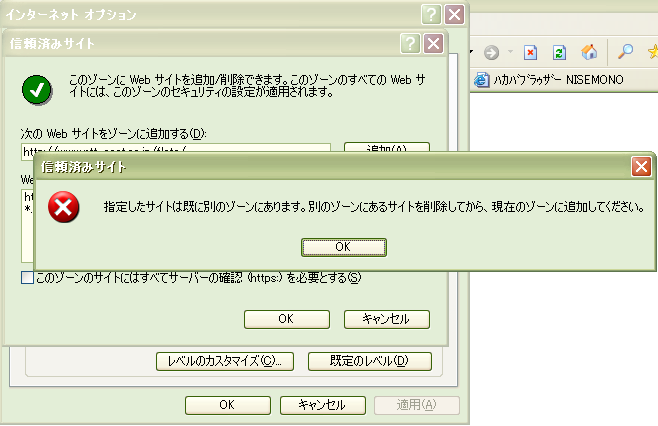
で、その後、某サイトにアクセスしたら全く何も起きず。これは Flash を使っているサイトだと分かっていたので、例によって「信頼済みサイトゾーン」に登録しようとしたのですが……。
よく見ると、そのサイトは件の方面に属していて、件のサーバ上にあるコンテンツだったのです。IE の「信頼済み」「制限済み」はドメインごとに登録という形になっていて、ディレクトリごとに登録すると言うことはできません。ですからこれを「信頼済み」に登録しようものなら、クロスサイトスクリプティング脆弱性の存在する某方面総合トップページも信頼してしまうことになります。そんなことはできないので、見ること自体を断念するという結果に相成りました。
ちなみに、制限済みサイトゾーンでは「ページの自動読み込み」もデフォルトでオフになっています。META refresh による遷移も一切動作しません。
リファレンスの table の記述の中にあった typo を修正。
Section 10.6.1 の height に関する Errata。これって Minor typo なのでしょうか。
select要素を使うときに、デフォルトで選択されている項目が「選択してください」などという文言になっていて、option をラベルとして機能させているケースがあります。たとえば「謎のselect要素」の最初に出てくる例がそうで、まさに「選択してください↓」という option がラベルとして機能しています。
私はこういう option の使い方はあまりよろしくないと思うわけですが、この「option をラベル的に使うのはよろしくない」という主張を、私はかつてどこかで読んだような記憶があるのです。しかし、それがどこだったのか思い出せません。WCAG1.0に書いてあったのかと思って読み返してみましたが、そうでもないようですし。
この議論、私はどこで目にしたのでしょうか。
CSSリファレンスの white-spaceの項目において、適用対象が「ブロック要素」となっていたのを「全ての要素」に修正。これは Errata in REC-CSS2-19980512 で訂正されています。
どうでもいいのですが、Section 8.5.4 の Errataに
Change the two lines "Value: [ <'border-top-width'> || <'border-style'> || <color> | inherit" to
Value: [ <border-top-width> || <border-style> || [<color> | transparent] | inherit
とありますが、左右のブラケットの数が合っていません。正しくは、
Value: [ <'border-top-width'> || <'border-style'> || <color> ] | inherit
to
Value: [ <border-top-width> || <border-style> || [<color> | transparent] ] | inherit
のような気が。まあ言っていることは分かるので問題ありませんが。
いろいろ調べ物をしていたら spam の RFC を発見したのでメモしておきます。多くの人には既知なのかもしれませんが。
RFC2635 - DON'T SPEW A Set of Guidelines for Mass Unsolicited Mailings and Postings (spam*)
セキュリティホール memo に IE の凄いホゥル の話が出ています。どうも XML の CDATA 区間の中に object を書かれると、何故か「マイコンピュータ」ゾーンのセキュリティレベルで実行されてしまうようです。
普通は「マイコンピュータ」ゾーンのセキュリティレベルはカスタマイズ出来ないので死亡するしかありません。が、「[IE4] セキュリティ ゾーンのレジストリ エントリについて」辺りを見つつレジストリをいじれば何とかなりそうです。そもそも「マイコンピュータ」ゾーン自体を編集可能に設定してしまうのが良いかもしれません。
注意! 以下の作業はレジストリ変更を伴う危険なものです。失敗すると Windows が起動しなくなるなど、致命的な障害が発生する可能性があります。もちろん Microsoft 非公認の作業であり、何の保証もありませんので行うときは覚悟して行ってください。もちろん、Microsoft のパッチを当てて解決するのがまっとうな手段であり、とりあえずの応急手当に過ぎないことも忘れないで下さい。
と、一発打ち上げたところで作業の内容に入りますが、.reg という拡張子のファイルにこんな内容を書いて……
REGEDIT4 [HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Internet Settings\Zones\0] "Flags"=dword:00000001
右クリックして「結合」すると、「インターネットオプション」の「セキュリティ」タブの中に「マイコンピュータ」ゾーンが追加されて編集可能になります。「未署名の ActiveXコントロールのダウンロード」を「ダイアログを表示する」か、「無効」に設定すればとりあえずは OK です。
こうしておくと「マイコンピュータ」ゾーンのセキュリティレベルが変更できるので、ローカルの JavaScript を無効にすることも出来ます。ただし、そういうことをすると例によってローカルで IE の機能を使っている部分(ダイアログの一部とか、ヘルプとか)がおかしくなったり、いろいろな弊害が出ます。そういった覚悟ができている人だけ行うようにしてください。
……って、そのまま「ご意見番」に追加するべき内容だったかもしれませんが、とりあえずここに書いておきます。
CSSリファレンス-レンダリングの typo を修正。
ロックマンさんによると、ホームページリーダーが display: none に対応した模様です。
それはそれで良いのですが、残念ながらどうも @media に対応していないようです。対応していないから @ルール全体を読み飛ばす、というのなら CSS2 のエラー処理規則に合致していて全く問題ないわけですが、@media screen ルールの中を何事も無かったかのように適用してくれるのはちょっと……。
HTML::Templateモジュールのドキュメントに、こんなことが書かれています。
Note: even though these tags look like HTML they are a little different in a couple of ways. First, they must appear entirely on one line. Second, they're allowed to "break the rules". Something like:
<IMG SRC="<TMPL_VAR NAME=IMAGE_SRC>">
is not really valid HTML, but it is a perfectly valid use and will work as planned.
not really valid とありますが、そんなことはありません。属性値に "<" と ">" が含まれていますが、引用符で括られた属性値は RCDATA としてパースされるので、< などが出現してもマークとはみなされないのです。RFC1866 3.2.4. Attributes にも
NOTE - Some historical implementations consider any occurrence of the `>' character to signal the end of a tag. For compatibility with such implementations, when `>' appears in an attribute value, it should be represented with a numeric character reference. For example, `<IMG SRC="eq1.jpg" alt="a>b">' should be written `<IMG SRC="eq1.jpg" alt="a>b">' or `<IMG SRC="eq1.jpg" alt="a>b">'.
などという例が出ていました。仕様的には属性値の中で > を使っても開始タグ終了区切り子とはみなさないことが分かります。
ということで、そのようなマーク付けは実は valid なのです。もちろん、RFC1866 に書いてあった通りオススメできない書き方ではありますし、XML では
[10] AttValue ::= '"' ([^<&"] | Reference)* '"' | "'" ([^<&'] | Reference)* "'"
ですので、XHTML では invalid ですが。
なお、
<IMG SRC="<TMPL_VAR NAME="IMAGE_SRC">">
と書くと、HTML 的に valid ではなくなります。
HTTP/1.1 には 303 See Other というステータスがあります。
しかし Netscape Navigator 4.7 は、ステータス 303 を受け取ってもリダイレクトしません。もちろん Location フィールドはちゃんと出力しているのに、です。
303 See Other は HTTP/1.0 にはありませんでしたから、HTTP/1.1 に対応していない UA の動作として不思議は無いのですが。
Note: Many pre-HTTP/1.1 user agents do not understand the 303 status. When interoperability with such clients is a concern, the 302 status code may be used instead, since most user agents react to a 302 response as described here for 303.
IE6 では、[インターネットオプション] - [セキュリティ] - [レベルのカスタマイズ] で「ページの自動読み込み」をオフにすれば META Refresh によるクライアントサイドのリダイレクトを無効化出来ます。これで「戻るボタンが効かない」などの罠も回避できます。
ちなみに、この設定でもサーバサイドで 301 や 302 や 303 を発行している場合はリダイレクトします。
文字参照一覧の typo を修正。
Netscape-Enterprise/4.0 な Web サーバにおいて、Accept-Language でコンテント・ネゴシエーションを行っているようなリソースがとにかく 404 Not Found になります。私以外の人には見られたりするようなので、私の日ごろの行いが悪いのかと思ってイロイロ調べてみたら、原因がわかりました。
私の IE6 の要求ヘッダには、Accept-Language: ja,en;q=0.8,de;q=0.5,*;q=0.3 が含まれています。要するに第一希望日本語、第二希望英語、第三希望ドイツ語です。それらが無い場合は、406 Not Acceptable を返されるよりは、読めない言語でも構わないので何かリソースを返して貰った方が良いので、* を入れています。
で、これが Netscape-Enterprise/4.0 では駄目なようです。Accept-Language: *;q=1 でも 404 になります。Accept-Language: * で要求すると 200 OK なのですが、* の後ろに qvalue がつくと問答無用で 404 Not Found になるようです。
いやーすばらしい。406 ならまだしも、404 になる辺りがなんともバグっぽいと言うか、きっぱりバグです。ちなみに RFC2616 では、
Accept-Language = "Accept-Language" ":"
1#( language-range [ ";" "q" "=" qvalue ] )
language-range = ( ( 1*8ALPHA *( "-" 1*8ALPHA ) ) | "*" )
qvalue = ( "0" [ "." 0*3DIGIT ] )
| ( "1" [ "." 0*3("0") ] )
です。*;q=1 は正当です。
って、今まで誰も気づかなかったのでしょうか。Accept-Language に * を含めているのって、ひょっとして私だけ?
ちなみに、Accept-Language でネゴシエーションしないリソースは問題なく拾えます。なので、フレームの外枠だけは拾えるなどという謎な状態になったりします。
もちろん、Apache ではこんな変なことにはなりません。ASAHIネットやもののけサーバに置いてある鳩丸はだいたいあんしんです。
リファレンスのtextareaの項目にちょこっと追記。
textarea要素の中身は #PCDATA です。CDATA ではありませんから < > & などをそのまま書いてはいけません。
が、どうも Netscape6は、textarea内に < や > などが大量に出現している文法違反のソースに出くわすと、本来 #PCDATA であるべきところに CDATA のデータを突っ込んでしまったものだと判断し、CDATA として処理するようです。大量の < や > にまぎれて & が入っていると、& とならずにそのまま & と表示されます。IE で同じものを表示すると、& となります。
エラー処理方法は仕様で定められていないので、IE の動作も Netscape6 の動作も誤りとは言えません。
久々に IANA の character-sets を拾いに行ったらhttp://www.iana.org/assignments/character-sets に移転しておりました。
「クレイフィッシュはもう終わりか?」……ここだけの話ですが、ホームディレクトリの名前が顧客のドメイン名で、その上のディレクトリが World Readable になっていたりすると、ls の結果を片っ端から whois するだけで顧客リストが完成したりします。whois は実に簡単なプロトコルなので、whois コマンドが無くてもスクリプトを書けば楽勝。InterNIC なら代表者の名前や電話番号まで拾えますから、それはさくっと持って行かれるでしょうなぁ。
ちなみに私はそこまではやっていないので念のため。むしろ エラーメール日記の 2001.02.07 にあるようなむちゃくちゃな事になってたりしたのがまずかったような気もしますし。
やっぱり私自身は見えていないわけではないので、どんな属性値が指定されていると助かるのかということがイマイチ理解できていません。とりあえずホームページリーダーV2.5のテーブル利用法あたりを参考にしつつ、素早く目的のセルを読むために役立つようなことを書いておくのが良いのかしら、と思ったり。今は summary に対応していなくても、将来は対応するでしょうから……って、3.1 で既に summary に対応していたりするのでしょうか?
互いに独立してランダムの意味がわかりません。
考えられる意味としては、単に「両者は同じ乱数系列に属するので、最初に得られた値から次の値を推測することができる」とかその辺でしょう。その辺がどうしても気になる場合は、time か何かを使って求めた回数分 rand を実行してみるとか、そんな方法があります。PGP の公開鍵を作るときにテキトーにキーを押すことを求められたりしますが、キーストロークの時間を計って似たようなことをやっているのだと思います。ってこのへんはむしろ TOM neko さん宛ですが。
ちなみにその前に ZnZ さんが言っているのは、わざわざ srand(time|$$) とか書くのが何のためなのかサッパリ分からない、ということだと思われます。$$ との or を取ることによって、試行ごとに違う乱数系列が採用される確率はむしろ低下してしまっています(たとえば time の下五桁が 00001 で $$ が 1110 のときと、time の下五桁が 11110 で $$ が 1111 のとき、or 合成の結果を取ると両者は同じになってしまう)。素直に srand(time) の方が良い気がしますし、Perl5.004 以降では srand せずに rand() を使うと初回に自動的に srand(time) してくれるようになっているので、書かないほうがマシではないかという話です。
or のかわりに xor を使うのはどうよ? でも、Perl での xor の取り方なんて知りませんが(無責任)。
xor を取るには time^$$ とします。が、これもやはり time と $$ の値によっては同じ値になってしまいます。こちらについては、perldoc に
Frequently called programs (like CGI scripts) that simply use
time ^ $$
for a seed can fall prey to the mathematical property that
a^b == (a+1)^(b+1)
one-third of the time. So don't do that.
などと書かれていたりして。
だいたいやね「正しい」と冠しただけでうさん臭くなるんですよ。この際「愛と感動の」を冠してみればいかが? 「愛と感動の歴史」とか。それみろってんだ、べらんめぇ。(google で「正しい」や「愛と感動の」を検索してみる?)
とりあえず「愛と感動のHTML4.0+CSSリファレンス&作法」というのが浮かびましたが、どうでしょうか。
もっとも、件の本はそれでも「正しい」の意味を定義していましたから、何をもって「正しい」としているのかサッパリ分からないという悲惨な状況ではありませんでしたが。
3.2.2. Server-based Naming Authority
URL schemes that involve the direct use of an IP-based protocol to a
specified server on the Internet use a common syntax for the server
component of the URI's scheme-specific data:
<userinfo>@<host>:<port>
where <userinfo> may consist of a user name and, optionally, scheme-
specific information about how to gain authorization to access the
server. The parts "<userinfo>@" and ":<port>" may be omitted.
server = [ [ userinfo "@" ] hostport ]
The user information, if present, is followed by a commercial at-sign
"@".
userinfo = *( unreserved | escaped |
";" | ":" | "&" | "=" | "+" | "$" | "," )
Some URL schemes use the format "user:password" in the userinfo
field. This practice is NOT RECOMMENDED, because the passing of
authentication information in clear text (such as URI) has proven to
be a security risk in almost every case where it has been used.
別に Flash が嫌いで「Flash 読めない」とか突っ込んだわけではなくて、そもそも「こーゆーデザインにすると怒られるかも」とか名指しで言われたので、「怒る以前に読めませんが」とか返したという話。
自作の BakeraCSV.pm を使って作った CGI で、空の値を送ると何故か Perl が応答しなくなるという現象が発生、Perl のゾンビプロセスが 20個くらい出来ていた。何故かループ 3回目までは問題なく動くのに 4回目のループでこけて応答無し、などという謎の現象。本気で原因不明。
いや、実は新生鳩丸掲示板を Perl5 の OOP を駆使して書き直そうかと思っているのですが、これがなかなか難しく……。そもそも Perl5 の OOP はホンモノの OO じゃないというご意見もありますが。
いっぱいあります。
新生鳩丸掲示板のスクリプトとかその他の Perl スクリプトもアーカイブが消滅しまくっているので、ダウンロードできません。ぼちぼちと復活させますので。
Permission が無くて読めず。くっ、かつての権限があれば……。
でも remotehost.txt てのがあったので、何をやってるのかは大体想像がつきました。そんなことしなくても LOG を grep 出来ますが。
実は今の鳩丸の背景色は #f8fff0 という微妙な指定になっていて、全然 Web セーフカラーではありません。
ここで言う「Web セーフ」とは、フルカラーの環境でも、256色の環境でも同じように発色することを指すものです。「どの環境でも同じ色に見えて欲しい」と考える人は、Webセーフカラーにこだわるでしょう。しかし、「環境によって色が違って見えても良い」と考えている私などは、特にこだわったりはしないのです。
どこぞのすき焼き屋でえむけいさんに「白にしか見えない」とか言われて、「私のトコでも白にしか見えない」と答えた記憶があります。
似たような文字色と背景色を使うと、色数が少ない環境では読めなくなる可能性があります。Web セーフカラーだけを使うようにすると、そのような事態を避けやすいということはあるでしょう。しかしそれは Web セーフカラーを使うことと直結しているわけではありません。Web セーフ云々は、原則としてアクセシビリティとは関係のない話です。
いや、もうね、馬鹿かと。アホかと。ALIZに感染しちゃう時点でかなり間抜けですが、それがサイバーテロ攻撃だと言うなら、私など何十回、いや百回以上はサイバーテロ攻撃に遭っています。ALIZ の whatever.exe も、Badtrans の s3msong.MP3.pif もしっかり持ってます。幸い、誰かと違って喰らったりはしていませんが。
hirokiazuma.com。div class="center" とか書かれているのを見て、『動物化するポストモダン』p144 以降の記述の信憑性が急激に低下してきたり。
むう、「CSS2勧告邦訳について」くらいは読んでおかないとなあ。それにしてもCSS3というのはまだ無いのだろうか。
そういえばもうずっと前に、clip のとこの「CSS2では、値の種類<shape>として正当な値は矩形のみである。
」というのは誤訳ではないかとメーったのですが、反応がなくて残念な思いをしたことを思い出しました。届いてなかったのかしら。岡橋さんは今年の年末は暇があるようなことを言ってたような気がするので、この機会にひととおりまとめてメーってみると良いかも。
CSS3 はまだですが、これもまた(?)モジュール化されていますので、五月雨式に出てくるはずです。CSS: under construction で Roadmap を確認してみると、まず Selectors が来年 6月に Recommendation になる予定のようです(現在のステータスは Candidate Recommendation)。
いまさらとは思いつつも、ひっそりとCSSリファレンスを更新。まだ完成にはいたらず。
石川雅康さんから得た情報によると、XHTML1.1 の DTD に未定義のパラメータ実体があってパース出来ないという話は、MSXML が悪いということらしいです。XML1.0(Second Edition) でも明確には書かれていないのですが、要は上から順にパースしていってマーク区間が IGNORE であると判明した時点でそこは飛ばすという挙動が正しい模様。しかし、そもそも何で未定義のパラメータ実体があるのかしら……。
ともかく、XHTML1.1 の DTD が腐っているわけではなく、MSXML が腐っていると言うのが W3C 的な結論のようです。
a要素の中に ruby 要素を含めた場合、IE6 ではルビ文字にまで下線がつきます。挙動としては正しいのかもしれませんが、なんか間抜け……。
長らく使っていないニフティのメールアドレスに mp3.pif という拡張子の添付ファイルがついたメールが来ていました。ヘッダが読めないのがなんとも……。
IE6 ではテキスト入力(input type="text")の入力内容を保存しておくことが出来ます。入力欄で何も入力せずに下キーを押すと履歴が出てきて選択できます。ここまでは知っていましたが、履歴のうちひとつを選択した状態で Delキーを押すとその履歴だけ削除できる、ということに今日始めて気付きました。
うまく使えば意外に便利かも。
HTML4.01 9.2 には
KBD:
Indicates text to be entered by the user.
とあります。これだけだとちょっと分かりにくいかもしれませんので、HTML2.0 でどうなっていたか(過去形)を見ると、
The <KBD> element indicates text typed by a user, typically rendered in a mono-spaced font. This is commonly used in instruction manuals. For example:
Enter <kbd>FIND IT</kbd> to search the database.
こんな感じです。ユーザによってタイプされる部分だけを kbd 要素としてマーク付けするのが正解です。
真・技術系メーリングリストFAQ。11/07 に追加されている質問、何のことを言っているのかまる分かりで笑いました。
<xsl:template match="abbr"> <xsl:variable name="title"><xsl:value-of select="@title" /></xsl:variable> <xsl:variable name="abbrcount"><xsl:number count="abbr[@title = $title]" format="1" /></xsl:variable> <abbr> <xsl:if test="@title"> <xsl:attribute name="title"> <xsl:value-of select="@title" /> </xsl:attribute> </xsl:if> <xsl:apply-templates /> </abbr> <xsl:if test="$abbrcount = 1"> (<xsl:value-of select="@title" />) </xsl:if> </xsl:template>
もうちょっとスマートに書けそうな気もするのですが。
そもそも、どうやって生成したものなのかはちゃんと書いてあるわけですし。
こんなのは良くあると思いますが……
while($line = <IN>){
$line =~ s/$foo/$bar/;
}
$bar にでかい文字列を渡して回したら、なんか Windows2000 全体が不安定に。ActivePerl の正規表現の処理ルーチンにメモリリークがあるのかしら? Windows2000 なんですが……。
Cookie Data in IE Can Be Exposed or Altered Through Script Injection.
about: スキームにこんな効力があったとは。いやー素晴らしいの一言に尽きます。常にスクリプトオフを推奨したい勢いですが、Cookie 必須のサイトに限ってスクリプトオンでないと動かなかったりするような……。
Halfwidth and Fullwidth form の文字はどうもうまくないようです。
xt の問題なのか、java の問題なのかは分かりませんが……。
<!DOCTYPE>
W3C(HTMLの標準化団体)のWAIガイドライン。
HTML文書ファイルの先頭に記述し、そのHTMLファイルで使用しているHTMLのバージョンなどを宣言します。
<記入例> これは、通常ソースの1行目に記入します。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
「W3C の WAI ガイドライン」。意味はさっぱり分かりませんが、なにやら迫力を感じます。
今まで原則としてローカルでの CGI 動作テストには AnHTTPd を使って来ましたが、故あって Apache1.3.22 for Win32 を導入してみました。
なんか、CGI がことごとく動かないのですが……。
スクリプトの一行目に書かれている Perl のパスなんてのはシェルによって解釈されるので Win 環境では関係ないと思っていたのですが、Apache for Win32 だと、サーバ自らそれを読み、それにもとづいて子プロセスとして Perl を起動してくださるようです。なので、サーバ上の Perl のパスとローカルのそれとが違っているとそのままでは動きません。
AnHTTPd だと、サーバの側で Perl のパスを設定できたりするのですが……。
秘密っぽいのでごそっと引用したりはしませんが、550 Dialups/open relays blocked. というのがステキ。MAPS の DUL みたいなものでしょうか。
むしろ From: を騙ろうとした spammer が失敗した感じですね。でなきゃ、Cc: にあんなに列挙しないでしょうし。送信に使われたサーバも ORDB に登録されてます……って、ORDB のサイト、いつから日本語版ができたのでしょうか。
CSS化が済んでいれば、XHTML化は簡単です。しかしMac IE5で表示させようとすると、DOCTYPEの所で「XML ファイルの解析中にエラーが発生しました。」と出て止まってしまい、何も表示されません。これは、なぜかサーバにアップロードすると大丈夫なんですね。ローカルだけで問題。
ローカルでは text/xml, サーバ上では text/html とみなされているためではないかと思います。HTML としてパースすると問題ないが、XML としてパースするとエラーが出ると。
ちなみに、「XML ファイルの解析中にエラー」になるのは、おそらく XHTML1.1 の DTD の中に未定義の実体があるからです。要するに DTD が腐っています。対処法としては、自分で DTD を書くとか。typical usage の SYSTEM 識別子が相対 URI なのはそのためなのではないかとさえ思いました。
Another HTML-lint gateway の HTTP 要求ヘッダに Host: が追加されたという話なのですが、これが私の中では大きな謎だったりします。というのも、Name based virtual domain なサーバのリソースは前からチェックできていたのです。たとえば問題のえび日記も、Host: を送らないと
GET /~bakera/shadow-zero/diary/ebi HTTP/1.0
HTTP/1.1 302 Found Date: Fri, 02 Nov 2001 04:39:42 GMT Server: Apache/1.3.20 Sun Cobalt (Unix) mod_ssl/2.8.4 OpenSSL/0.9.6b PHP/4.0.3pl1 mod_auth_pam_external/0.1 FrontPage/4.0.4.3 mod_perl/1.25 Location: http://www.web50.net/~bakera/shadow-zero/diary/ebi Connection: close Content-Type: text/html; charset=iso-8859-1
こんなのが返って来てボツなのです。なのに Host: が追加される前からチェックできていたという……。
どうして?
本当だ、えび日記って読めるじゃん。日記ブラウザの指定が良くないのか、正しいけどもじらが悪いのか、どっち。
がーん。text/xml と text/html のコンテントネゴちゃんなんですが、サポート掲示板のやりとりとか読まれていないのでしょうか。
ちなみに当初はちゃんと XHTML1.1 なリソースを出力していたのですが、アンテナ側が UTF-8 を読めないと言うことだったので US-ASCII にしようと思ったら xsl:output method="xml" だと encoding に何を指定しても何故か UTF-8 になってしまうという罠があり、泣く泣く method="html" にして US-ASCII 版を生成しています。
ただし、XSLT の側は本来 XHTML1.1 になることを想定しているものなので、出力されているのはかなり謎なマークアップになっています。また、HTML 版は手動で生成しているのでつくるのが面倒です。というわけで、しばしば更新はサボられます。
IE6以降、あるいは IE5以降 + MSXML3.0 の人には XML 版をオススメします。
というか、text/xml が処理できないブラウザなら、Accept: text/html で要求してくれれば HTML 版が配給されるようになっているのですが……。
Internet Explorer 6 における CSS の拡張。
!DOCTYPE 宣言は、Standard Generalized Markup Language (SGML) の宣言の 1 つで、ドキュメントが理論的に準拠する文書型定義 (DTD) を指定します。この宣言は、終了タグのない HTML タグに似ていて、感嘆符 (!) で始まり、属性の名前と値の個々の組み合わせをトークンで示します。この宣言は、ドキュメントの先頭で、HTML タグの前に指定する必要があります。
宣言の名前って感嘆符で始められたっけ……?
マーク宣言に属性ってあったっけ……?
ま、なんだかんだ言って Acid Test も問題なさそうですし、ようやく CSS1 に対応できてきたという感じでしょうか。
うがっ、パクられたっ!
お礼になんかくれっ!
どうして「メールマガジン配信用ASP」と ASP ご指名なんだろう。個別技術をどうこう言うべき記事ではなかろうに。
私も「どうしてだろう?」と思ったのですが、
メールマガジン配信用ASP」とは「まぐまぐ」や「メルマ!」のようなメール配信サービスを提供している会社を指しているのではないでしょうか?
これでやっと分かりました。ASP は Active Server Page ではなくて、Application Service Provider だったのです。私は本気で Active Server Page だと思っていました。おそらく小島さんも同様だったのでしょう。
略語を迂闊に使うと混乱を招く、という事例でした。
あの人に分からないような話題はこっちに。
プライヴェートな話題はあっちに。
で、2001年10月25日のえび日記ですが、空のaなら<a href="uri"/>の方が書くのが楽なのでは?
XML 的には <a></a> も <a/> も同じなので、もちろん <a/> と書くことも出来ます。が、私は <a/> という書き方はもっぱら内容モデルが EMPTY なものに使い、そうでないものについては終了タグを書くようにしているので、内容を持ちえる a要素については <a></a> という書き方になっています。
XHTML の後方互換性のためのやり方を純粋な XML にも適用しているような感じですが、ebi-diaryML(仮称)は a や p など HTML っぽい要素をいくつか持ってはいるものの、本気で純粋な XML なので、<a/> と書いても全く問題ないったらありゃしないのです。
というか、よく考えたら <a href="uri"></a> と書くより、<a>uri</a> と書くようにして href を補った方が良いような気がしてきました。
google で "B" encoding を検索。上位の結果を一通り見てみましたが、単なる Base64 を "B" encoding と呼んでいるケースはなく、メールヘッダで使われる =?ISO-2022-JP?B? というような形式のみが "B" encoding と呼ばれている雰囲気です。The "B" encoding と定冠詞をつけて呼ばれていたり、あとは混同を避けるためか MIME "B" encoding と頭に MIME をつけて呼んでいるケースもあるようですが。
更新履歴を更新。
って冗談みたいですが、HTML と関係ない話題を追いやってすっきりさせました。
この前のやつ、position() ではなく <xsl:number level="single" count="foo"/> で取得した値を使えば余計なテキストノードがカウントされないので改行があっても無くても融通が利く。
まじめな XSLT プロセッサはちゃんと DTD を読んで、DTD で定義されている属性値の初期値や #FIXED とされている属性値を補完してくれる。
apply-templates に select を指定すると既存の文書を楽に扱えることがある。たとえば XHTML の場合、body に対するテンプレートで apply-templates select="p" とすると body 直下に #PCDATA が書いてあるようなモノを無視できる。活用すべし。
split($accept_lang, /,\s*/) がうまく動作しなくて悩みました。正解は split(/,\s*/, $accept_lang)。パターンが先です。
たとえば、http://homepage1.nifty.com/bakera/html/hatomaru という URL を入力すると、これは NOT Found になります。ASAHIネットと違って MultiViews が効いていないからです。
そのこと自体は問題ないのですが、末尾に .html が必要なことに気づいて URL を入力しなおそうとすると、ちょうどそれに気づくのを見計らったようなタイミングで http://homepage.nifty.com/ にリダイレクトされてしまい、修正しようとしていた URL も消えてしまうのでした。URL を修正するために許された時間は、わずか 5秒です。
いやー素晴らしい。WCAG1.0 7.4 に Until user agents provide the ability to stop the refresh, do not create periodically auto-refreshing pages. [Priority 2]
と書かれている意味が身にしみて理解できました。
ここでtext-align:centerを指定すると、
中央部にレンダリングされる。と思っていたのだけど何かが間違っているらしい。
いえ、間違ってないです。センタリングされます。ちなみに最後の図のようになるのは、ちょうどテキストと同じ幅の width が指定されているような場合です。
テキストがただ一行におさまる短いもので、かつ border もなにも無ければ、text-align: center は margin: auto でセンタリングしたのと同じような挙動になります。
そうならないのだとしたら、やっぱりブラウザがなんか変なのでしょう。
Active Perl だと ppm ってのがあって CPAN.pm のようにモジュールをインストールできたりするのですな。知りませんでした。
勘違いしていた理由の一つに、要素は横幅一杯の幅が有るものだと思っていたのがあります。border付けたりすると割と広い範囲で枠がつくし。
それはあながち間違いでもないです。特に何もしなければブロック要素には横幅いっぱいの幅があります。
要素の幅が踏んでいるテキストの大きさによって変動するのであればナビゲータ4.xのborderの挙動が正しいということになりそうですが、何がどう違うのやら。
いえ、中身のテキストの量によって横幅が変わることは原則としてありません(中身のテキストがはみ出すことはあります)。よって、Netscape4.x の挙動は明らかに変です、というか border を指定すると挙動が変わるってどういうことなのか小一時間問い詰めたいところです。
要素の大きさはどこで決まるのだ。
CSS2 10.3あたりに書いてあります。
たとえば、通常フローにある非置換ブロックの幅は、
'margin-left' + 'border-left-width' + 'padding-left' + 'width' + 'padding-right' + 'border-right-width' + 'margin-right' = width of containing block
となるように算出されます。margin, padding の初期値は 0 で、border の初期値は medium ですが border-style: none であれば幅は 0 と計算され、width の初期値は auto ですから、これらが何も指定されていないときは width が containing block の幅と同じに、その他は全て 0 になります。
ちなみにH1要素のテキストがはみ出たりクリッピングされる理由が未だに判らないのですが、要素の高さってドコで決まるのだ? なんでパディング領域を突破したりするのだろう。謎。
高さは10.6 Computing heights and marginsの方を見てください。
If 'height' is 'auto', the height depends on whether the element has any block-level children. If it only has inline-level children, the height is from the top of the topmost line box to the bottom of the bottommost line box.
height の初期値は auto なので、特に何も指定しない場合は、インラインボックスしか含まない h1 要素の高さは中身の量で決まります。
自分自身にも先祖要素にも height の指定がないなら、はみ出ると言うことはまずありません。それなのにはみ出たりする場合は、日ごろの行いかブラウザの実装のどちらかが悪いものと思われます。
XHTML1.0 Second Editionのワーキングドラフトが出ている模様。' の互換性についてなど、細かい注意書きが追加された他、
HTML 4 defined the name attribute for the elements a, applet, form, frame, iframe, img, and map. HTML 4 also introduced the id attribute. Both of these attributes are designed to be used as fragment identifiers.
とかなんとかで HTML4.0 ベースの記述だったものが HTML4.01 ベースに移行していますが、DTD には反映されてない……?
DTD 的には、参照されてない実体が消されたとか、accesskey やらなにやらが %focus という実体にまとめられたとか、微妙な変更にとどまっている模様……と思ったら html要素や head要素をはじめとするいくつかの要素に id 属性が追加されている模様。これは HTML4.01 にも無いのですが。
XSLT テンプレートの中で XML で定義されていない文字実体参照を使おうとすると少し厄介ですが、数値文字参照ならば自由に使えます。しかも xt だと   を入力して html で出力すると になっていたりしていやー素晴らしいと言うか。
yuuさんの電波を受信しつつ完成?
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method="xml"/> <xsl:template match="/"> <xsl:apply-templates/> </xsl:template> <xsl:template match="foo"> <xsl:if test="position() mod 4 = 2"> <xsl:text disable-output-escaping="yes"><bar></xsl:text> </xsl:if> <foo><xsl:value-of select="current()"/></foo> <xsl:choose> <xsl:when test="position() mod 4 = 0"> <xsl:text disable-output-escaping="yes"></bar></xsl:text> </xsl:when> <xsl:when test="current() = ../foo[last()]"> <xsl:text disable-output-escaping="yes"></bar></xsl:text> </xsl:when> </xsl:choose> </xsl:template> </xsl:stylesheet>
美しくない……。もっとスマートなやり方ってないのっ?
ちなみに foo要素と foo要素の間にある CRLF も一つのノードとして扱われていて、position() はそれもカウントした値を返している模様。
<foo>1</foo> <foo>2</foo> <foo>3</foo> <foo>4</foo> <foo>5</foo>
となっているとき、これを二つずつグループ化して
<bar> <foo>1</foo> <foo>2</foo> </bar> <bar> <foo>3</foo> <foo>4</foo> </bar> <bar> <foo>5</foo> </bar>
のようにする XSLT テンプレートってどう書けば良いのでしょうか。各 foo について処理するのは xsl:for-each で楽勝なのですが、二個ずつというのはちょっち……。
IEっていうかCSS
IE5.0だと意図したとおりだけど、IE5.5、IE6だとH1要素がはみ出ているような。IE6だとtext-align: centerも効かないし謎。
IEっていうかCSS
HTML 4.01 Transitionalだとtext-align: centerが有効になる模様。
コレってStrictでは削除だったっけ。うーむ調べられん。Air H"買うか。
width が 100% 未満のブロック要素に text-align: center を指定すると要素の中のテキストはセンタリングされますが、要素自体はセンタリングされません(書字方向に応じて左か右によることが期待される)。ブロック自体をセンタリングするには、そのブロックの margin-left と margin-right を共に auto にします。
……というのが CSS の仕様的には正しい動作なのですが、過去の IE などは text-align: center でブロック自体をセンタリングするという実装になっていました。IE6 ではこの誤りが一応訂正されているので、センタリングされません……が、HTML4.01 Transitional を使っていたり、文書型宣言の SYSTEM 識別しがない場合は過去の実装との互換性を重視する「互換モード」で動作することになっていて、ブロック自体がセンタリングされます。
「tableレイアウトをやれと言われたらやりますか?」と問われて、「やりますよ」と即答したら、なんだかちょっと残念そうな顔をされてしまいました。
私は、「table レイアウトするなら summary は空にすべし」と主張しているくらいですから table レイアウトは否定していないわけですし、ユーザエージェントの互換性もかなり重視しているのですが、あんまり理解されてないのかしら。研究者的見地から「DTD的にはこうなってる」と発言することはあっても、「だからそうしろ」とまでは言っていないのですが、まあ早とちりされても仕方ないのかも。ちなみに、HTML4.01 Transitional を使うなとも思ってないです。Q&A参照。
リファレンスはよく紹介されているし誤字の指摘もしばしばあるので結構参照されている気がするのですが、ご意見番とか Q&A とかはそもそもあんまり読まれていないのかも。そもそも「W3C は font 要素は良くないって言ってるみたいだけど、なんでよ?」などという疑問が鳩丸のメインだったわけなのですが……というか、まず古い文書をメンテナンスしましょう > 私。
掲示板に投稿しようとすると core 吐いてこけるのですが、なんで?
Perl スクリプトが core 吐くってのはよっぽどのことだと思うのですが……。昔からたまにあるんだよなぁ。
フリーの音声読み上げブラウザ(?)VE2000でこの更新履歴を読むと 100% の再現率で落ちる、という報告をいただいて、いろいろやってみたのですが、動作にいたりませんでした。うう。
というわけで落ちる原因はいまだ不明です。申し訳ない。誰か分かる人がいらっしゃいましたらよろしくお願いします。
ちょこっとスタイルを変えてみました。CSSに対応していない環境では変化なし。
HTML4では大文字が推奨だったのにXHTMLでは小文字のみになったっていうのは何故?というのを先月の最後にcommitし忘れていたので再掲。
大文字/小文字に関するQ&A もあるのですが、そもそも Q&A なんてあんまり読まれてないのかも……。
ぜんぜん関係ありませんが IE5.5SP2 で「ユーザ補助」の「Webページで指定された色を使わない」を有効にするとユーザスタイルシートの色指定まで無視されます。それって「Webページで指定された色」ではないと思うのですが。
みつかささんのお力添えにより、掲示板の URI リンクのバグを修正。
http://www.so-net.ne.jp/kids/。IE5.5 SP2 でアクセスしてるんですが……。
BODY要素直下の要素をposition:absoluteにしてbottom:0pxにすると、MacOS版IE5ではBODY要素の一番下に移動し、Windows版IE5.5とNetscape6では一番上にスクロールした状態でのウインドウの一番下に移動する。どっちが正しいのだろう。
おそらく、Windows版IE5.5とNetscape6では、ウインドウのスクロールバーはBODY要素のoverflow:scrollの効果で出てきているという事になっている気がする。つまり実際のBODY要素の大きさはウインドウの大きさしかなくて、後ははみ出している状態だと。MacOS版IEでは、ウインドウのスクロールは別途定める部分が担当しているので、BODY要素ははみ出さない状態で存在している。そう考えればどちらも正しいのだが、実装の違いで移動する位置が違うという様なことでいいのだろうか。
CSS2 の仕様的な言葉を使うなら、"initial containing block" が違うということになります。CSS2 10.1 Definition of "containing block" では以下のようになっています。
The containing block (called the initial containing block) in which the root element lives is chosen by the user agent.
要するにルート要素の containing block は UA 異存なのです。その意味では「どちらも正しい」のですが、CSS2 9.1.2 Containing blocks の定義を読むと、
The width of the initial containing block may be specified with the 'width' property for the root element. If this property has the value 'auto', the user agent supplies the initial width (e.g., the user agent uses the current width of the viewport).
The height of the initial containing block may be specified with the 'height' property for the root element. If this property has the value 'auto', the containing block height will grow to accommodate the document's content.
initial containing block の幅はビューポートの幅に、高さは内容量全てが収まる高さにするという例が出ています。これに近い実装は MacOS版 IE5の方です。